


 ChatGPT
ChatGPT
 Perplexity
Perplexity
 Claude
Claude
 Grok
Grok

Wenn ein Computer die menschliche Art des Lernens imitiert, dann sprechen wir von Machine Learning.
Wie ist Maschinelles Lernen entstanden?
Angeregt und inspiriert von neuronalen Prozessen im Gehirn, entstanden bereits vor einem halben Jahrhundert erste Ideen und Projekte im Bereich der künstlichen Intelligenz. Schnell hat sich Maschinelles Lernen daraus als eine Schlüsseltechnlogie herausgebildet.
Heute kommen wir tagtäglich mit künstlicher Intelligenz in Berührung, auch wenn wir es gar nicht bemerken. In Form von personalisierten Produktempfehlungen beim Online-Shopping, als Gesichtserkennung beim Entsperren unseres Smartphones oder Spamfilter für unsere E-Mail-Programme – durch die sprunghaft angestiegene Rechenkapazität und enorm großen Datenmengen vereinfacht Machine Learning heute unseren Alltag und das Berufsleben.
Wir erklären Dir, was Machine Learning genau ist, welche Arten unterschieden werden und wie Dein Unternehmen mit künstlicher Intelligenz Wettbewerbsvorteile gewinnt.
Übrigens: Entdecke unsere Weiterbildungen im Bereich Data Analytics und Data Science und bekomme sie dank Bildungsgutschein unter bestimmten Voraussetzungen sogar kostenlos.
Was bedeutet Machine Learning?
Machine Learning oder auch Maschinelles Lernen ist ein Teilgebiet der künstlichen Intelligenz und befähigt technische Systeme wie Computer bzw. Algorithmen automatisch, aus Mustern zu lernen und sich nach und nach weiterzuentwickeln. Je mehr Datenpunkte hinzukommen und je öfter gelernt wird, desto genauer trifft der Algorithmus Zuordnungen und Vorhersagen.Die Grundlage für diese automatisierten Lernprozesse bilden ausgefeilte Algorithmen. Darunter kann man sich eine Art Bauanleitung als Abfolge von Schritten und Regeln vorstellen, mithilfe derer eine Aufgabe gelöst wird. Diese Algorithmen werden auf vorhandene Datensets angewendet und erkennen selbstständig Muster und Gesetzmäßigkeiten, um im Anschluss passende Lösungsansätze abzuleiten.
Dabei ist die Genauigkeit der Entscheidungen, die der Algorithmus trifft anfänglich noch nicht sehr hoch, steigt aber mit der Zeit und mit jedem wiederholtem Durchlauf. Die gewonnenen Erkenntnisse lassen sich anschließend verallgemeinern und können dann auch auf neue, unbekannte Datensets angewendet werden, um beispielsweise Vorhersagen zu treffen.
Die Modelle des Machine Learnings generieren also Wissen auf Basis von bereits gemachten Erfahrungen. Diese Eigenschaft bietet enormes Potenzial und unterscheidet maschinelles Lernen von der traditionellen Programmierung. Dort werden die Regeln, nach denen Algorithmen Lösungen für Probleme generieren, vom Menschen per Hand programmiert und angewendet.
Im Zuge der Digitalisierung und im Zeitalter von Big Data ist die Menge an produzierten Daten allerdings viel zu groß, um für jede Problemstellung händisch geeignete Algorithmen zu entwickeln. Daher setzen immer mehr Unternehmen maschinelles Lernen ein, um effizienter und schneller zu arbeiten.

Maschinelles Lernen: Welche Arten gibt es und wie werden sie unterschieden?
Um verschiedenste Problemstellungen mit Machine Learning zu lösen, haben sich unterschiedliche Arten des maschinellen Lernens herausgebildet. Es werden grundlegend drei Arten unterschiedenen:
- Supervised Learning (überwachtes Lernen)
- Unsupervised Learning (unüberwachtes Lernen)
- Semi-supervised Learning (halb-überwachtes Lernen)
- Self-supervised Learning (selbst-überwachtes Lernen)
- Reinforcement Learning (bestärkendes Lernen)
- Deep Learning (tiefes Lernen)
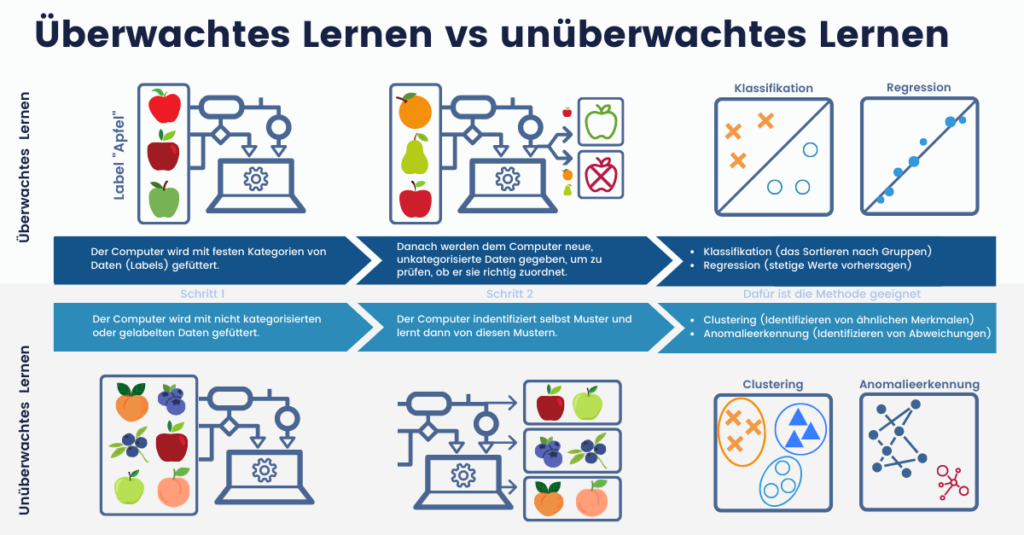
Supervised Learning
Supervised Learning, auch überwachtes Lernen genannt, nutzt vorkategorisierte Daten zum Lernen. Diese Daten werden zunächst durch den menschlichen Lehrer (z. B. Data Scientist) entsprechend einer bekannten Logik mit der Lösung beschriftet, bevor sie in die Machine-Learning-Modelle eingespeist werden.
Der Algorithmus lernt anhand dieses Trainingsdatensatzes, Muster und Zusammenhänge zu erkennen. Sind die Muster korrekt, wendet er sie auf neue Eingaben an. Wer sich mit Machine Learning befasst, muss ihr wichtigstes Gesetz kennen: Garbage in, garbage out. Je besser die Qualität der Trainingsdaten ist, desto zuverlässiger kann der Algorithmus die richtige Antwort liefern.
Ist die Qualität der Daten schlecht, kann der Algorithmus keine verlässlichen Entscheidungen treffen. Wenn der Algorithmus also lernen soll, Chihuahuas als solche zu identifizieren, dann dürfen ihm im Trainingsdatenset auch nur qualitativ gute Bilder von Chihuahuas vorliegen, die keine falschen Informationen (Blaubeer-Muffins) enthalten.
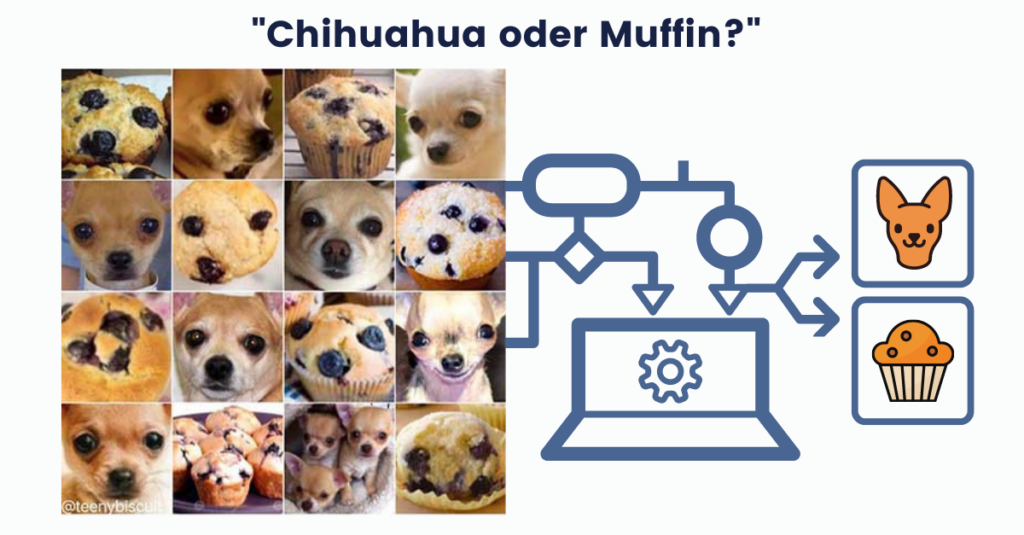
Supervised Learning wird in der Praxis für Klassifikationen oder Regressionen angewendet. Auf diese Weise können beispielsweise Kunden auf Grundlage ihres Kaufverhaltens bestimmten Käufergruppen zugeordnet oder der Stromverbrauch eines Haushaltes mit Hilfe von Vergangenheitsdaten vorhergesagt werden.
Unsupervised Learning
Unsupervised Learning, auch unüberwachtes Lernen genannt, bekommt im Gegensatz zum Supervised Learning keine vorkategorisierten Lösungen. Es ist es die Aufgabe des Algorithmus, selbstständig Strukturen innerhalb der Daten anhand ihrer Eigenschaften zu erkennen und sie entsprechend zu strukturieren und zu differenzieren.
Damit können interessante oder nicht offensichtliche Muster erkannt werden, welche einem Menschen verborgen geblieben wären. Allerdings müssen die gefundenen Gruppen im Nachhinein durch den Menschen eingeordnet und bewertet werden, denn der Algorithmus liefert keine Begründung, warum er auf diese Weise gruppiert hat.
Angewendet wird Unsupervised Learning beispielsweise in der Spracherkennung zur Identifizierung von Nutzersprachgewohnheiten für Assistenzsysteme wie Siri oder Alexa. Außerdem können zum Beispiel Funktionsprobleme bei Maschinen durch unüberwachte Verfahren zur Erkennung von Anomalien oder durch vorausschauende Wartung behoben werden.
Reinforcement Learning
Reinforcement Learning, auch bestärkendes Lernen genannt, bildet eine besondere Herangehensweise an maschinelles Lernen. Der Algorithmus interagiert mit seiner Umwelt und lernt durch Versuch und Irrtum. Er bekommt allerdings nicht gezeigt, welche Aktion oder Handlung in welcher Situation richtig ist. Dafür werden ein Belohnungssystem und eine Kostenfunktion festgelegt, die verschiedene Aktionen entweder mit zusätzlichen Punkten bestärken oder mit dem Abziehen von Punkten bestrafen.
Der Algorithmus muss nun selbstständig eine Strategie zur Lösung des Problems erlernen, indem er die Punktzahl versucht zu steigern und so das beste Ergebnis zu liefern. Reinforcement Learning wird in der Praxis beispielsweise bei Einparkassistenzen angewendet, die Objekte in der Umwelt erkennen und darauf abgestimmt den optimalen Weg zum Einparken anzeigen. Andere Anwendungen bilden verschiedene Optimierungsprobleme beispielsweise in der Logistik oder Energiewirtschaft ab.
Semi-supervised Learning
Das sogenannte semi-überwachte Lernen ist eine Mischung aus überwachtem und unüberwachtem maschinellem Lernen. Innerhalb des Trainingsdatensatz befindet sich dabei eine kleine Stichprobe von gelabelten Eingabedaten. Dadurch lernt der Algorithmus neue Kennzeichnungen für nicht gelabelte Daten zu generieren.
Ähnlich wie beim induktiven, menschlichen Denken lernt der Algorithmus zu abstrahieren, was er gelernt hat und auf unbekanntes anzuwenden. So zum Beispiel beim Klassifizieren von Textdokumenten.
Self-supervised Learning
Das sogenannte selbst-überwachte Lernen bedeutet, dass der Algorithmus aus einem kleinen Datensatz von nicht gelabelten Beispieldaten gebildet wird und eigene Ausgabebezeichnungen erzeugt. Der Algorithmus unterteilt dabei die eingegebenen Daten und lernt, wie die einzelnen Teile zueinander in Beziehung stehen.
Es wird zum Beispiel bei unvollständigen oder beschädigten Daten angewendet, um die Lücken in einem Text zu füllen oder wird im Bereich der Verarbeitung natürlicher Sprache (NLP) eingesetzt. Im Unterschied zum Supervised und Semi-supervised Learning lernt der Algorithmus ohne gelabelte Daten. Außerdem unterscheidet es sich zum Unsupervised Learning dadurch, dass es nur aus einem kleinen Trainingsdatensatz lernt, statt aus einem großen.
Deep Learning
Deep Learning ist eine weiterentwickelte Form des Machine Learnings. Es besteht aus drei oder mehr Schichten (Layer), die wiederum aus Knotenpunkten (Nodes) bestehen. Diese Knotenpunkte sind das technische Äquivalent zu Neuronen im menschlichen Gehirn.
Die erste Eingabeschicht empfängt eingehende Daten, die Knotenpunkte leiten alle Informationen an die anliegende Knotenpunkte der versteckten Schicht weiter. Dabei werden die weitergegebenen Informationen gewichtet. Soll der Algorithmus also Chihuahuas erkennen, so wird den Merkmalen des Hundes mehr Gewicht gegeben als dem Hintergrund in dem er sich befindet.
Die Aktivierungsfunktionen, durch die die Informationen geleitet werden, entscheiden darüber, ob eine Information weitergereicht wird oder nicht. Die letzte Schicht ist die Ausgabeschicht, die aus nur zwei Knotenpunkten besteht. Je nachdem welcher Knotenpunkt mehr „Gewicht“ weitergeleitet bekommen hat, meldet der Algorithmus, ob es sich um einen Chihuahua handelt oder nicht.
Wo wird Maschinelles Lernen eingesetzt?
Im vorangegangenen Kapitel haben wir Dir bereits gezeigt, für welche Funktionen die unterschiedlichen Arten des Machine Learnings eingesetzt werden können. Jetzt gehen wir noch näher darauf ein, in welchen Bereichen Maschinelles Lernen bereits eingesetzt wird und wie wir davon profitieren.
-
Industrie: Qualitätskontrolle, Predictive Maintenance
-
Finanzwesen: Betrugserkennung, Kreditrisikobewertung
-
Gesundheitswesen: Diagnoseunterstützung, Medikamentenentwicklung
-
Handel: Preisoptimierung, personalisierte Angebote
-
HR / Recruiting: Skill-Matching, automatisierte Lebenslaufanalyse
Machine Learning in der Mobilität
Im Bereich des autonomen Fahrens und der Mobilität der Zukunft bilden die aus Sensoren, wie Radaren oder Kameras, gesammelten Daten eine umfangreiche Datenbasis. Machine-Learning-Algorithmen erfüllen in diesem Zusammenhang verschiedene Aufgaben. Beispielsweise müssen autonom fahrende Autos Objekte in der Umgebung erkennen und identifizieren, um dann vorherzusagen, ob und in welche Richtung sich diese Objekte in den nächsten Sekunden bewegen werden.
Machine Learning in der Medizin
Auch im Bereich der Medizin werden täglich durch Bluttests, Röntgenaufnahmen oder ärztlichen Berichten Unmengen an Daten produziert. Mithilfe von Machine-Learning-Algorithmen können Ähnlichkeitsanalysen von Patientendaten dabei unterstützen, Muster und Zusammenhänge in Krankheitsverläufen zu erkennen. Außerdem sind Algorithmen mittlerweile sogar in der Lage, basierend auf bildgebenden Verfahren, Vorstufen von Krebszellen zu erkennen und somit die Qualität der Früherkennung zu verbessern.
Machine Learning im Marketing
Ein weiteres Anwendungsgebiet bildet das Marketing und die individualisierte Kundenkommunikation. Das Kaufverhalten von Kunden liefert neben geographischen oder zeitbezogenen Daten auch Informationen zu Präferenzen und Vorlieben. Basierend darauf können Verhaltensmuster gefunden und Zielgruppen segmentiert werden. Machine-Learning-Algorithmen helfen darüber hinaus die personalisierte Kundenkommunikation zum richtigen Zeitpunkt zu optimieren. Durch individuelle und auf die Kunden abgestimmte Produkte und Maßnahmen, kann die Loyalität und Kundenzufriedenheit einfach gesteigert werden.
AI Driven Management
Ein AI Driven Management-Training ist speziell für Führungskräfte entwickelt. Du bekommst einen Gesamtüberblick über moderne Anwendungsmöglichkeiten von KI in datengetriebenen Unternehmen und erhältst strategische Handlungsempfehlungen für die Ableitung einer KI-Strategie sowie die passenden Managementkompetenzen, um künstliche Intelligenz auf Projekt und Unternehmensebene auszurollen.
Welche Skills brauche ich für Machine Learning?
Um im Bereich Machine Learning erfolgreich zu arbeiten, brauchst du eine Kombination aus technischen, analytischen und methodischen Fähigkeiten. Die wichtigsten Grundlagen sind:
- Python: Die Programmiersprache Nummer 1 für Machine Learning. Mit Bibliotheken wie pandas, NumPy, scikit-learn, TensorFlow oder PyTorch lassen sich Daten analysieren und Modelle trainieren.
- Statistik & Mathematik: Ein grundlegendes Verständnis von Wahrscheinlichkeiten, Verteilungen, Regression und linearer Algebra ist entscheidend, um die Funktionsweise von Algorithmen zu verstehen und Ergebnisse richtig zu interpretieren.
- Data Engineering: Daten müssen aufbereitet, bereinigt und in geeignete Formate gebracht werden. Kenntnisse in SQL, ETL-Prozessen und Datenpipelines helfen dir, große Datenmengen effizient zu verarbeiten.
- Cloud Computing: Viele Machine-Learning-Projekte laufen in der Cloud – zum Beispiel mit AWS, Google Cloud oder Microsoft Azure. Hier lernst du, Modelle zu deployen, zu skalieren und produktiv zu nutzen.
Tipp: Wenn du gerade erst einsteigst, konzentriere dich zuerst auf Python und Statistik. Danach kannst du dein Wissen Schritt für Schritt um Data Engineering und Cloud-Themen erweitern.
Was sind typische Einstiegsjobs im Machine Learning?
Der Einstieg in die Welt von Machine Learning und Künstlicher Intelligenz ist vielfältig – und es muss nicht gleich der Titel „KI-Forscher:in“ sein. Viele Unternehmen suchen Einsteiger:innen mit praktischem Verständnis für Daten und Algorithmen. Typische Rollen sind:
- Data Analyst: Du arbeitest mit großen Datensätzen, visualisierst Trends und leitest Handlungsempfehlungen ab. Machine Learning kann hier z. B. zur Prognoseanalyse eingesetzt werden.
- Machine Learning Engineer: Du entwickelst und trainierst ML-Modelle, implementierst sie in Anwendungen und optimierst sie für den produktiven Einsatz. Dafür brauchst du fundierte Kenntnisse in Python, Statistik und Softwareentwicklung.
- KI-Berater: Du hilfst Unternehmen dabei, KI-Strategien zu entwickeln, geeignete Use Cases zu identifizieren und Datenprojekte erfolgreich umzusetzen. Neben technischem Wissen brauchst du hier auch Kommunikations- und Beratungskompetenz.
Auch Data Scientists, MLOps Engineers oder Business Intelligence Specialists gehören zu den häufigen Rollen im erweiterten Machine-Learning-Umfeld.
Der Berufseinstieg gelingt am besten über datennahe Rollen – und entwickelt sich mit wachsender Erfahrung schnell weiter Richtung KI-Engineering oder Beratung.
Wie lange dauert es, Machine Learning zu lernen?
Wie schnell du Machine Learning lernst, hängt stark von deinem Vorkenntnisstand, Lernziel und Zeitaufwand ab. Grundsätzlich kannst du dich an folgenden Richtwerten orientieren:
- Schneller Einstieg (1–3 Monate): Grundlagen in Python, Statistik und Datenanalyse. Ideal für alle, die verstehen möchten, wie Machine Learning funktioniert, ohne selbst Modelle zu entwickeln.
- Praxisorientiertes Wissen (3–6 Monate): Aufbau von ML-Kompetenzen durch Projekte und praxisnahe Übungen – z. B. in einem berufsbegleitenden Onlinekurs oder Bootcamp. Danach kannst du einfache Modelle selbst erstellen und bewerten.
- Berufliche Spezialisierung (6–12 Monate): Vertiefung in Themen wie Deep Learning, NLP oder Data Engineering. Hier entwickelst du Fähigkeiten, die für ML-Engineering oder Data-Science-Jobs notwendig sind.
Tipp: Der effektivste Weg ist „Learning by Doing“. In projektbasierten Weiterbildungen lernst du praxisnah, wie du echte Datensätze analysierst, Modelle trainierst und Ergebnisse interpretierst.
Fazit: Was ist Maschinelles Lernen?
Bereits in vielen Bereichen unseres Lebens bestimmt Machine Learning unseren Alltag, auch wenn wir es oftmals nicht direkt merken. Ob beim Navigieren durch die Stadt, in unserem Social Media Feed oder bei der Automatisierung komplexer Prozesse in der Industrie. Die Anwendungsmöglichkeiten von Machine Learning sind vielfältig.
Möchtest nun auch Du das Entwickeln und Implementieren von Machine Learning Algorithmen erlernen oder Dein Team mit zukunftsrelevanten Fähigkeiten ausstatten? Dann haben wir die richtigen KI-Weiterbildungen für Dich.
Dein Einstieg ins Machine Learning.
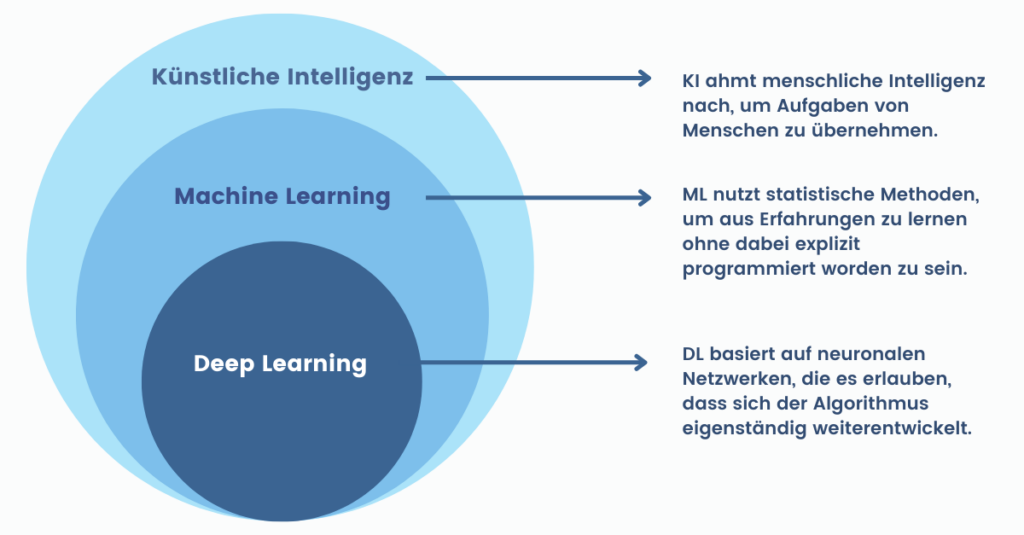
Kostenloser Grundkurs Machine Learning: Begriffe wie Künstliche Intelligenz, Maschinelles Lernen oder auch Deep Learning sind in aller Munde.
Aber was hat es mit den Begriffen auf sich und wie lassen sie sich voneinander abgrenzen?
Beim Maschinellen Lernen lernt ein Computerprogramm auf der Basis von Daten etwas über den Zustand der Welt.




